目录
前言
分析(x0)
分析(x1)
分析(x2)
分析(x3)
分析(x4)
总结
我有话说
前言
大家好,我叫善念,这是我的第三篇技术博文。音乐、小说、这次是视频,估计下次就是图片吧。
文章都是当天现写的,自己也没有去做过。
我们将要采集的网站是网页版的DY数据:目标网址
咱们随便选择一个博主的视频进行采集,我饿了我就找了个美食博主。
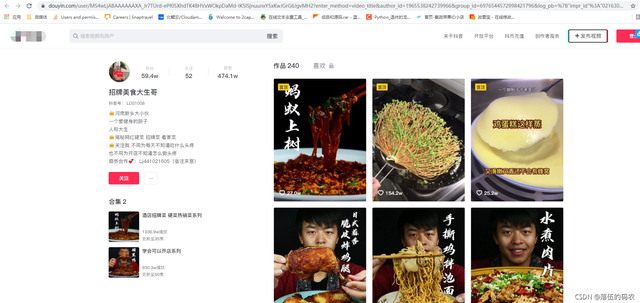
分析(x0)
在网页的元素中咱们可以找到当前视频的跳转链接:
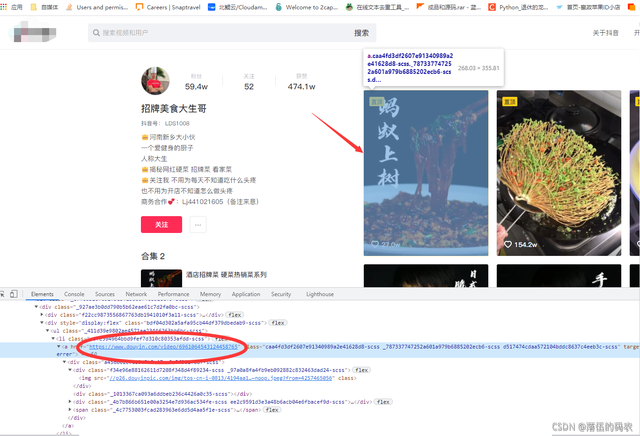
而经过我观察了一下我发现每个li标签都包含了一条短视频的信息:
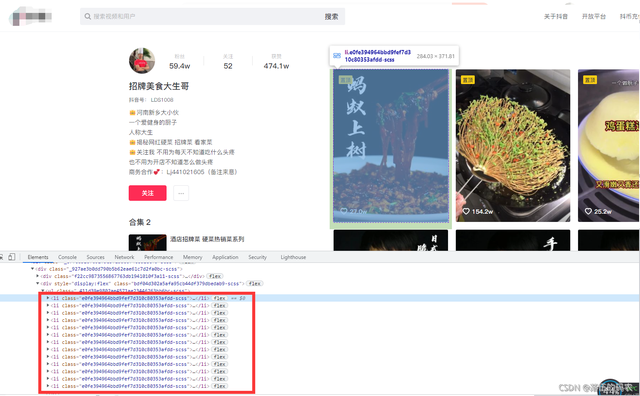
那么这里总共是13个li标签,而咱们的这个博主肯定不止发了13个视频吧?又不是我善念这种货色只有几十个粉丝,所以问题出在哪?
我已经猜到这个是一种瀑布流的模式加载视频了,跟大家解释一下。就是比如说一个网页上面你只能看到十条数据,当你拉动网页下滑条后它会自动加载一些新的数据出来。像瀑布一样数据流出来,原理很简单,就是你拉动下滑条的时候会触发JavaScript脚本生成一些新数据
来做个测试:
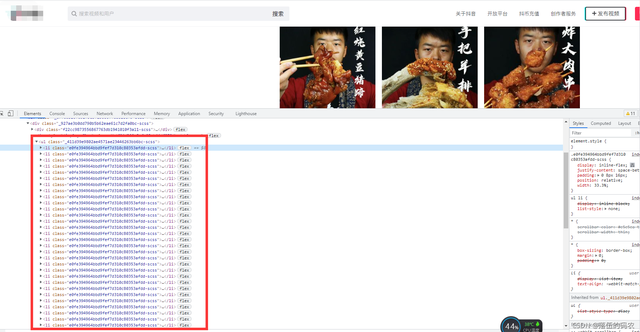
当我拉动浏览器的下滑条后,数据明显增多,改变了网页上的元素。
这里我再次解释一下,网页元素与网页源代码的区别:
网页元素:浏览器执行一些JavaScript渲染之后的一个呈现(所以它会改变)
网页源代码:服务器传给咱们浏览器的原始数据(经过浏览器的渲染后才会变成网页元素)所以原始数据是不会变化的。
那么瀑布流的一个优势是什么呢?明显就是降低服务器的一个负荷吧?用户想看多少数据就传输多少数据,而不是一股脑的全部加载完!
分析(x1)
也就是说明咱们根本无需去考虑网页源代码(因为不可变),已知网页的视频是由认为拉动浏览器下滑条执行JavaScript脚本然后通过接口传输数据给我们。
首先咱们可以观察得到,每个视频后面的那串数字就是视频对应的ID值,前面肯定是不变的。
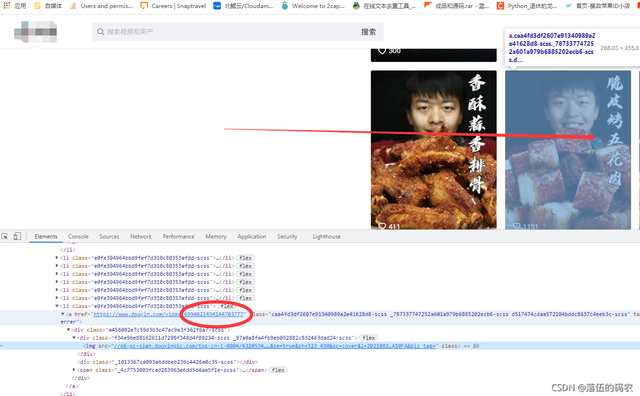
咱们直接抓包:
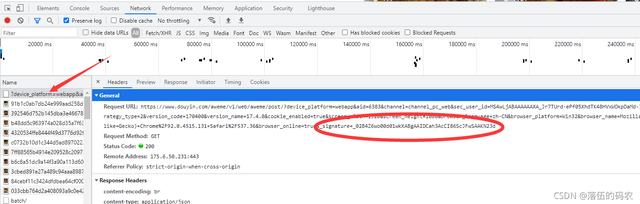
根据瀑布流的规律很容易抓到这个包,因为每滑动一下下拉条它就会生成一个新的这样的包
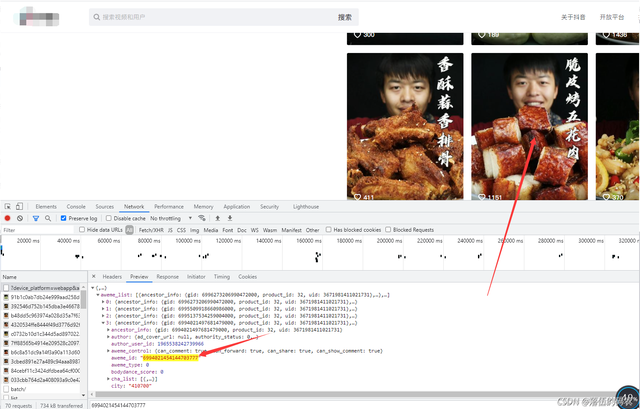
确实这个值是对应的,但是别忘了看我上上图圈出来的那个_signature参数,传说中的DY签名加密。其它值均为固定值都是一些电脑信息,浏览器的版本。只有这个_signature是加密的,自己去手动拉动下滑条多抓几个包就可以对比知道了。
分析(x2)
好吧,很多人觉得我会去解密这个参数,但是新版DY加密是有混淆的,就算是我能教各位也未必能学,所以我决定退而求次的用另外一种方法。
我们当时分析出,只要我们拉动滑块,那么在网页元素element中就会加载出新的视频资料,出现更多的li标签。
那么我们可以利用selenium去模拟人拉动下滑条吧?然后采集到视频的跳转链接,进行requests访问,问题就解决了!
但是得到视频跳转链接有什么用呢?
分析(x3)
咱们先点到视频里面看看:
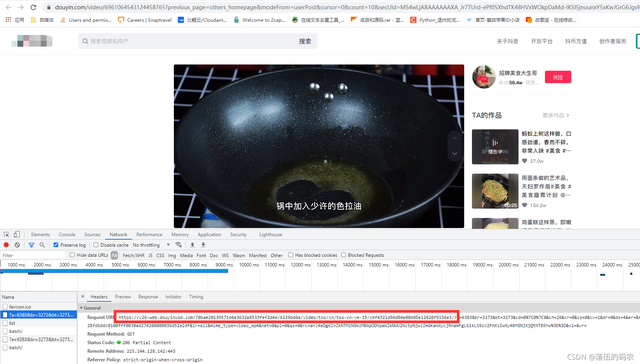
一下子就把视频的源地址抓到了,可是这个地址完全看不出任何的规律......不过经过我上次给你们讲的音乐的文章,你们应该知道如何分析了,首先这么长久尝试着删除一些参数,看是否还可以正常访问。最短并且可以访问的链接为我在红色框框的链接。
那么然后.......还是找不到规律,不知道如何生成的,抓包也发现此包之前就是一个图片的包而已。
分析(x4)
继续看网页元素中是否有咱们的视频源地址吧:
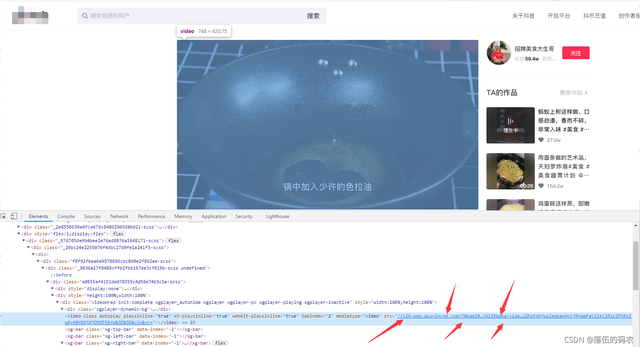
emmm果然有,我现在好希望源代码中也有,因为我前面采集跳转链接用了selenium已经降低了采集的速度,如果这里还是这样用selenium的话速度就太慢了。
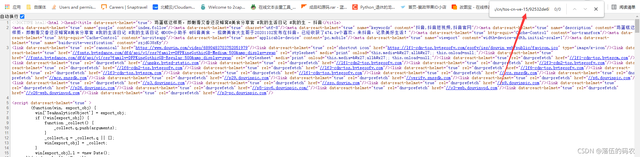
啥也没搜到......按道理我前面抓包它也没有JavaScript文件,就一个图片的包,没理由不存在网页源代码中的,我搜短一点试试:

不瞒你们说,我是自己第一次做,边写边研究的,纯粹的实战。就这个东西我刚才眼睛都看花了,它把url进行编码了,所以咱们看起来就很伤眼睛。
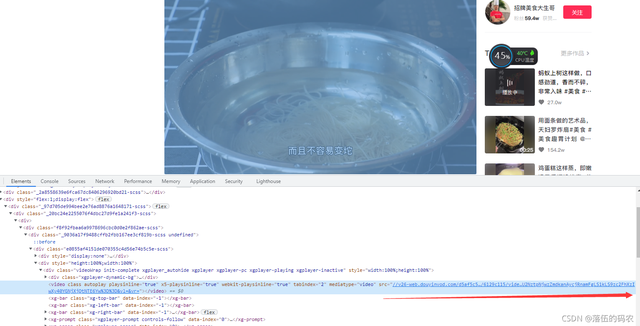
好吧,咱们只要采集到缩到最短的链接就可以了。
转码给大家看看:
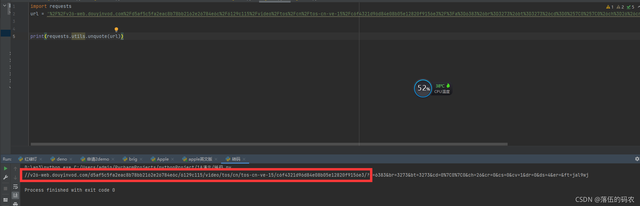
咱们只要红框中的即可。
那么到现在的话所有的流程思路是不是走完了?
先用selenium采集到跳转的url,然后用requests模块请求跳转的url,获取到视频源地址,最后请求源地址下载就好啦。
总结
这个只是采集单个博主的视频,那么能否整站采集所有的视频呢?我分析了一下,发现原理是一模一样的.....是可以的!
我有话说
你是否在找源代码?可惜了,我也是第一次做这个东西,我文章写完的时候就是我最后分析完的时候,我自己也没源代码。
—— 纸上得来终觉浅,绝知此事要躬行。
如果这样分析后还让有些朋友觉得有难度,那么我再给大家看一个我之前讲过的完美采集某宝的案例,selenium部分完美契合(在我主页的联系我中),requests部分就不说了,完全没什么技术含量的,就两个请求。
文章的话是现写的,每篇文章我都会说得很细致,所以花费的时间比较久,一般都是两个小时以上。
原创不易,再次谢谢大家的支持。
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
``` 当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢? 学习Python中有不明白推荐加入交流Q群号:928946953 群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF! 还有大牛解答! ```

