公号:码农充电站pro
主页:https://codeshellme.github.io
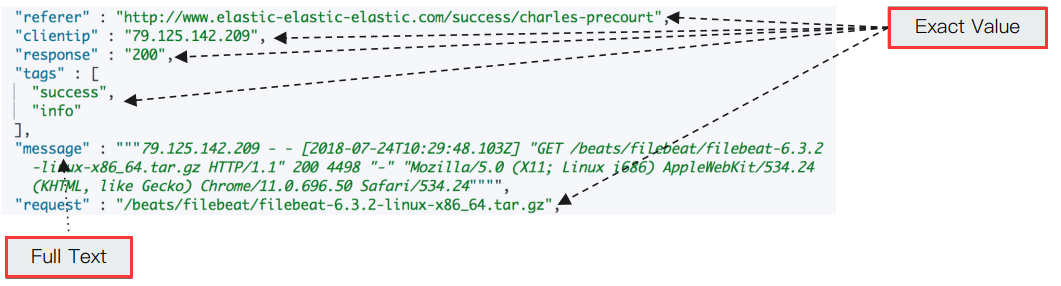
1,精确值与全文本
ES 中有精确值(Exact Values)与全文本(Full Text)之分:
- 精确值:包括数字,日期,一个具体字符串(例如"Hello World")。
- 在 ES 中用 keyword 数据类型表示。
- 精确值不需要做分词处理。
- 全文本:非结构化的文本数据。
- 在 ES 中用 text 数据类型表示。
- 全文本需要做分词处理。
示例:
2,分词过程
搜索引擎需要建立单词(Term / Token)与倒排索引项的对应关系,那么首先就需要将文档拆分为单词,这个过程叫做分词。
比如将 hello world 拆分为 hello 和 world,这就是分词过程。
3,分词器
ES 使用分词器(Analyzer)对文档进行分词,ES 中内置了很多分词器供我们使用,我们也可以定制自己的分词器。
一个分词器有 3 个组成部分,分词过程会依次经过这些部分:
- Character Filters:字符过滤,用于删去某些字符。该组件可以有 0 或多个。
- Tokenizer:分词过程,按照某个规则将文档切分为单词,比如用空格来切分。该组件有且只能有一个。
- Token Filter:对切分好的单词进一步加工,比如大小写转换,删除停用词等。该组件可以有 0 或多个。
4,ES 中的分词器
ES 有下面这些内置的分词器:
-
Standard Analyzer:默认分词器,按词切分,转小写处理,也可以过滤停用词(默认关闭)。
- 在 ES 中的名称为
standard
- 在 ES 中的名称为
-
Simple Analyzer:按照非字母切分,非字母会被去除,转小写处理。
- 在 ES 中的名称为
simple
- 在 ES 中的名称为
-
Stop Analyzer:按照非字母切分,非字母会被去除,转小写处理,停用词过滤(the、a、is 等)。
- 在 ES 中的名称为
stop
- 在 ES 中的名称为
-
Whitespace Analyzer:按照空格切分,不转小写。
- 在 ES 中的名称为
whitespace
- 在 ES 中的名称为
-
Keyword Analyzer:不做任何的分词处理,直接将输入当作输出。
- 在 ES 中的名称为
keyword
- 在 ES 中的名称为
-
Pattern Analyzer:通过正则表达式进行分词,默认为
\W+非字符分隔,然后会进行转小写处理。- 在 ES 中的名称为
pattern
- 在 ES 中的名称为
-
Language Analyzers:提供了30多种常见语言的分词器,比如:
-
english:英语分词器,会对英文单词进行归一化处理,去掉停用词等。- 归一化处理:比如
running变为run,goods变为good等。
- 归一化处理:比如
- 更多可参考这里。
-
5,测试分词器
我们可以通过下面的 API 来测试分词器:
GET _analyze
{
"analyzer": "AnalyzerName",
"text": "内容"
}
6,自定义分词器
当 ES 中的内置分词器不能满足需求时,我们可以定制自己的分词器。
在上文中已经介绍过一个分词器由 3 部分组成:
-
Character Filters:字符过滤,用于删去某些字符。
- 该组件可以有 0 或多个。
-
Tokenizer:分词过程,按照某个规则将文档切分为单词,比如用空格来切分。
- 该组件有且只能有一个。
-
Token Filter:对切分好的单词进一步加工,比如大小写转换,删除停用词等。
- 该组件可以有 0 或多个。
6.1,内置分词器组件
ES 对这 3 部分都有内置:
-
内置 Character Filters:
- HTML Strip:去除 HTML 标签。
- Mapping:字符串替换。
- Pattern Replace:正则匹配替换。
- 内置 Tokenizer:有 15 种。
- 内置 Token Filter:有将近 50 种。
Character Filters 示例:
# 使用 html_strip
POST _analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text": "<b>hello world</b>"
}
# 使用 mapping
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ "- => _"]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}
# 正则匹配替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "pattern_replace",
"pattern" : "http://(.*)",
"replacement" : "$1"
}
],
"text" : "http://www.elastic.co"
}
Tokenizer 示例:
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/user/ymruan/a/b/c/d/e"
}
Token Filter 示例:
POST _analyze
{
"tokenizer": "whitespace",
"filter": ["stop"],
"text": ["The gilrs in China are playing this game!"]
}
# 先 lowercase 再 stop
POST _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase","stop"],
"text": ["The gilrs in China are playing this game!"]
}
6.2,自定义分词器
自定义分词器需要使用 settings 配置,示例:
PUT index_name
{
"settings": { # 固定写法
"analysis": { # 固定写法
"analyzer": { # 固定写法
"my_custom_analyzer": { # 自定义分词器的名称
"type": "custom", # 固定写法
"tokenizer": "standard", # 定义 tokenizer
"char_filter": [ # 定义 char_filter
"html_strip"
],
"filter": [ # 定义 token filter
"lowercase",
"asciifolding"
]
}
}
}
}
}
# 更复杂的一个示例
PUT index_name
{
"settings": { # 固定写法
"analysis": { # 固定写法
"analyzer": { # 固定写法
"my_custom_analyzer": { # 自定义分词器的名称
"type": "custom", # 固定写法
"char_filter": [ # 定义 char_filter
"emoticons" # 在下面定义
],
"tokenizer": "punctuation", # 定义 tokenizer
"filter": [ # 定义 token filter
"lowercase",
"english_stop" # 在下面定义
]
}
},
"tokenizer": { # 自定义 tokenizer
"punctuation": { # 自定义的 tokenizer 名称
"type": "pattern", # type
"pattern": "[ .,!?]" # 分词规则
}
},
"char_filter": { # 自定义 char_filter
"emoticons": { # 自定义的 char_filter 名称
"type": "mapping", # type
"mappings": [ # 规则
":) => _happy_",
":( => _sad_"
]
}
},
"filter": { # 自定义 token filter
"english_stop": { # 自定义 token filter 名称
"type": "stop", # type
"stopwords": "_english_"
}
}
}
}
}
# 使用自定义分词器
POST index_name/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "I'm a :) person, and you?"
}
7,安装分词器插件
我们还可以通过安装插件的方式,来安装其它分词器。
比如安装 analysis-icu 分词器,它是一个不错的中文分词器:
elasticsearch-plugin install analysis-icu
analysis-icu 在 ES 中的名称为 icu_analyzer。
还有一些其它的中文分词器:
- IK 分词器
- THULAC:是由清华大学自然语言处理与社会人文计算实验室研制的一套中文分词器。
- hanlp 分词器:基于 HanLP。
- Pinyin 分词器
安装命令:
elasticsearch-plugin install analysis-ik
elasticsearch-plugin install analysis-hanlp
elasticsearch-plugin install analysis-pinyin
其它分词器:
(本节完。)
推荐阅读:
[ElasticSearch 安装与运行](https://www.cnblogs.com/codeshell/p/14371473.html
Kibana,Logstash 和 Cerebro 的安装运行
欢迎关注作者公众号,获取更多技术干货。
